
z2soo's Blog
Deep learning: CNN 개념 본문
목차
- FC : Fully Connected
- CNN : Convolutinal Neural Network
- CNN 기본 개념
FC : Fully Connected
Fully Connected layer 혹 Dense layer : 모든 node가 다음 layer의 모든 node에 연결되어서 학습되는 layer 구조를 의미하고, 지금까지 학습한 layer 구조는 모두 여기에 포함된다. Multi-layer multinomial logistic regression 과정에서 이전의 layer 출력값이 다음 layer 입력값으로 사용되는 구조가 이에 해당된다.
FC layer 특징
- 입력 데이터( 예: 한 사람에 대한 데이터 )가 1차원으로 표현되어야 한다.
사실 컬러 이미지는 가로 * 세로 * 깊이(명암) 으로 표현되는 3차원 데이터이다. 그렇지만 지금까지는 FC layer가 가지는 위와 같은 특징 (1차원으로 데이터를 표현) 으로 인해 2차원 이미지 (MNIST: MNIST는 컬러 이미지가 아닌 흑백 이미지로써 깊이 값이 없음) 를 1차원으로 변환하여 사용하여 학습을 진행했었다. 28 * 28 크기의 2차원 이미지 데이터를 784열을 가진 1차원의 데이터로 변환해서 사용한 것이다. 보다 효율적인 이미지 학습을 위해 Convolutional Neural Network를 사용한 방법에 대해 알아보겠다.
CNN : Convolutional Neural Network
이미지 데이터 구성
1장의 흑백 사진에 대한 이미지 데이터는 2차원이지만, 여러 장의 흑백 사진 데이터가 된다면 3차원이 되고, 마찬가지로 1장의 컬러 사진에 대한 이미지 데이터는 3차원 이지만, 여러 장의 컬러 사진 데이터가 된다면 4차원으로 입력된다.
- 1장의 흑백 사진 : width * height
- 1장의 컬러 사진 : width * height * color (depth, channel)
이처럼 실제 컬러 이미지 1장의 데이터는 3차원이고, 이를 학습시키기 위해서는 flatten(평면화) 시켜서 1차원으로 표현해야 한다. 그 과정에서 크기를 조절해야되기 때문에 공간에 대한 데이터를 유실할 우려가 있다. 이런 데이터 유실 위험성 때문에 학습과 예측 과정에서 문제가 발생한다. 공간 데이터 유실 위험성을 없애고, 이미지의 특성을 추출해서 학습을 용이하게 하기 위해 고안된 방식이 CNN 방식이다. CNN은 공간 데이터 유실을 최소화 시키고, 특색을 도출하고, 한장으로 여러 특색을 도출한다. deep learning 과정 이전에 CNN을 진행하고, 그 값을 FC layer(지금까지 우리가 한 과정)에 넣어서 학습과 예측을 진행한다.
이미지 학습의 한계
일반적으로 이미지 학습의 가장 큰 문제는 다음과 같다. (MNIST 제외)
- 굴곡진 이미지
- 서로 다른 크기의 이미지
- 각도가 변경된 이미지
이러한 문제들과 더불어서 이미지에 조금의 변형이 생겨나도 학습이 힘들어진다. 이미지가 항상 같은 각도, 크기, 형태로 주어지지 않기 때문에 학습이 더욱 어려운 것이다. 따라서 이미지 학습에서 가장 중요한 것은 그만큼 여러 종류의 이미지와 더불어 training image data의 갯수가 많아야 되며, 그에 따라 보다 긴 학습시간이 요구된다. 그리고 위와 같은 문제점들을 최소화 하면서 이미지 학습을 시키기 위해 등장한 Convolutional Neural Network에 대해 앞으로 학습해보도록 한다.
CNN 이란?
Convolutional Neural Network 라고 불리는 이 방식은 이미지를 학습시키는 것에 있어서 현존하는 가장 효율적인 방법이다. 즉, CNN은 이미지 처리에 특화된 알고리즘이라 할 수 있다. 이미지 학습을 위해서 많은 방법들이 연구되어졌고, 사람이 학습하는 방식 중 대상에 대한 특징을 인식하는 방식을 모델링하여 만들어졌다. 이는 이미지의 픽셀 값을 그대로 활용하는 것이 아니라, 이미지에 대한 특징을 도출하기 위해 여러 filter를 이용하고 이에 대해 특징을 labeling 하여 신경망에 넣어서 학습하는 방식을 활용한다.
하나의 이미지를 28*28 크기로 조정 및 다음과 같은 필터를 적용해서 도드라지는 특징에 대해 여러번 학습을 진행하는 방식!
포토샵 선명하게 하는 효과처럼 이미지를 sharp하게 만들어 학습
흑백 이미지로 변환하여 학습 ... etc
위의 과정을 통해 학습할 때, 필터가 늘어나는 만큼 학습에 걸리는 시간이 늘어나고, 따라서 필터의 수와 학습 시간이 늘어나면 보다 효율적으로 학습을 시키기 위해 이미지의 크기를 작게 조정하는 과정을 거친다. CNN에 대한 기본적인 개념은 꼭 숙지하도록 한다.
CNN 기본 개념
1. Convolution (합성곱)
입력된 이미지 데이터에 대해, 정의된 filter 데이터를 가지고 maping하여 각 값을 곱하여 더하는 연산을 수행하는 과정이다. Convolution (합성곱)이 수행되기 위해서 뒤에서 다룰 개념들이 활용되고, 이 과정에 대한 결과 값이 feature map으로 표현된다.
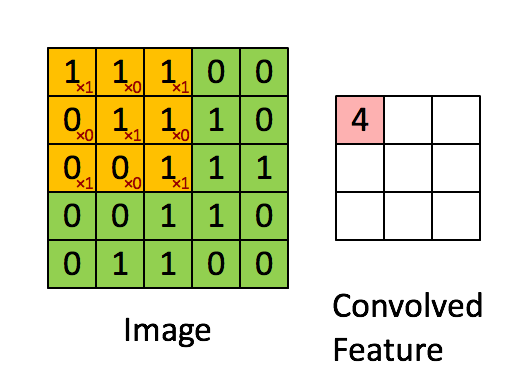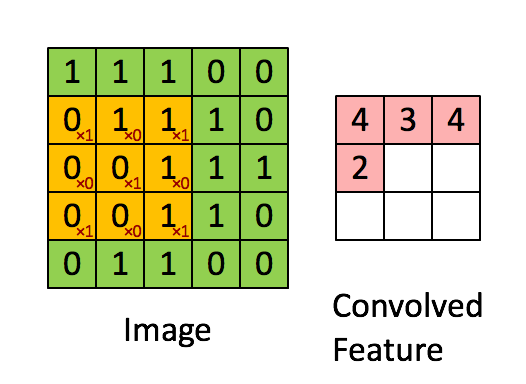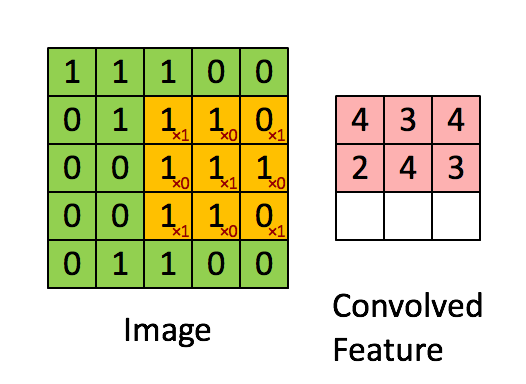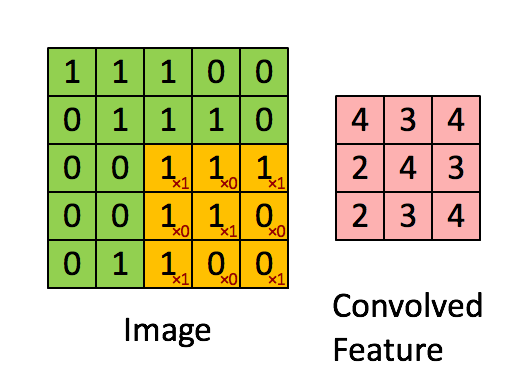

2. Channel, Depth
이미지 데이터를 표현할 때, width * height 외에 channel 혹은 depth 라고 하는 구성이 하나 더 붙는다. 컬러 이미지의 경우에는 BRG: Blue, Red, Green 의 channel 3 가지로 구성되어 있다. 그리고 흑백 이미지의 경우에는 grey 하나의 channel 만을 가진다. 이와 같은 개념 때문에 많은 사람들이 channel과 color를 동일선상의 개념으로 생각할 수 있으나 처음의 컬러 이미지 경우에만 해당될 뿐 filter를 적용하면서 filter의 갯수가 channel의 값으로 사용되기도 한다. 즉, channel은 이미지를 표현 중 하나의 방식 이라고 생각하는 것이 옳다.
예시
이미지 크기: 32 * 32 * 3
필터의 크기: 5 * 5 * 3
이처럼 필터의 크기는 내가 설정할 수 있지만, depth 혹 channel의 크기는 3으로 이미지와 동일한 크기여야 한다.
Channel 유의점
- channel != color, 이미지를 표현하는 하나의 방식
- input data의 channel 갯수 = output data의 channel 갯수
- input data의 channel 갯수 = filter의 channel 갯수
- 초기값 이후의 convolution 과정에서의 image의 channel 갯수 = 임의로 설정하는 filter 갯수
- pooling 과정에서 channel 수는 변화 x
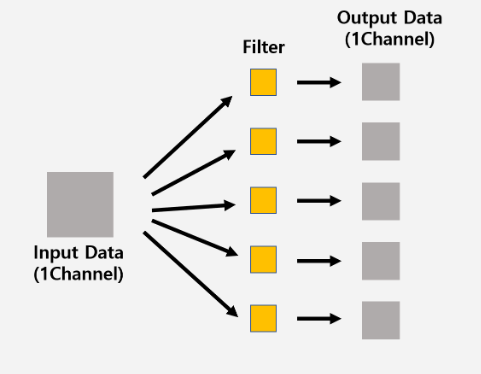

3. Filter, Kernel
filter 또는 kernel이라고 불리는 이 요소는 이미지의 특징을 찾아내기 위한 공용 파라미터이다. 일반적으로 (4,4), (3,3)과 같은 정사각 행렬로 정의되어지고 위에서 언급한 합성곱, convolution 과정에서 사용되어져 feature map 그리고 actication map을 출력하게 된다. sharpen, blur, 흑백 등과 같은 효과 필터 또한 3차원 (3차원 이미지에 적용시킬 것이기 때문) 의 형태를 취한다. sharpen, blur 등 종류를 말하였지만, 필터는 갯수 입력시 임의로 만들어진다.
filter를 적용하여 특징을 출력하는 과정에서 데이터의 크기가 작아지고 이미지 유실 가능성이 생긴다. 이러한 유실, 출력 데이터의 크기가 줄어드는 것을 방지하기 위한 방법으로 수행하는 과정이 padding 처리이다.
보통 pooling layer를 거치면 1/4로 출력이 줄어들기 때문에 convolution layer의 결과인 feature map의 개수를 4배정도 증가시켜서 filter 갯수를 설정한다.
4. Stride
filter를 어떤 간격으로 순회하면서 적용시킬지에 대한 설정으로 개인이 임의적으로 설정한다. 단, 행, 열의 순회 간격은 (1, 2) 처럼 다르게 줄 경우 오류가 날 수 있음으로 (1, 1)과 같이 동일하게 주도록 한다.
아래 padding 과정을 진행할 때, 만약 입력과 출력의 데이터 크기를 같게끔 padding = SAME 으로 설정한다면, stride의 크기는 (1,1) : [1,1,1,1]로 설정해줘야 된다.
5. Padding
아래 이미지로 보여지는 것처럼 convolution의 과정에서 출력되는 이미지 데이터의 크기가 작아짐에 따라 이미지 데이터 유실 가능성이 생긴다. 이러한 데이터 유실을 방지하기 위해 생겨난 방법이 padding 이다. padding은 ReLU 함수 적용 이후에 사용되며, padding 설정 (VALID, SAME) 은 개인의 판단에 의해 임의로 한다.
- VALID : padding 실행 x, 출력 데이터 크기가 작아짐
- SAME : padding 실행 o, 출력 데이터 크기를 입력 데이터 크기과 동일(same)하게 함

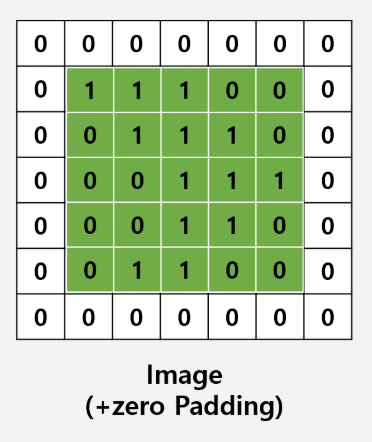
위와 같이 0으로 둘러싸는 padding을 zero padding이라고 한다. 상식적으로 생각해본다면 이미지의 주요 특징 및 요소는 중앙에 위치해 있으므로 이미지 주위에 0의 값으로 padding한다고 하여 특징에 큰 영향을 미치지 않기 때문에 가능하다. 이렇게 padding을 한다면 colvolution 과정을 실행해도 데이터 출력 값이 작아지지 않는다.
6. Feature map
feature map은 kernel( 이미지 데이터 )의 값과 필터 값을 곱해서 더하는 과정(convolution)을 통해서 출력되는 값이다. 이 과정으로 계속 값이 커진다. 따라서 필터를 계속해서 적용시킨다면 큰 값을 가진 feature map이 생성될 것이기 때문에 relu 함수를 적용시키는 것이다. (ReLU 함수: 너무 크거나 작아지지 않도록 원래 데이터의 크기를 조정하는 함수) 이 값을 입력값으로 해서 다시 convolution 과정을 반복하게 된다.
7. Activation map
최종적으로 convolution 과정을 통해서 나온 feature map의 모든 channel들을 모은 것이 activation map이다.
8. Pooling
이미지 자체의 크기가 너무 클 경우 그 크기를 가지고 FC layer로 가게 된다면 연산량이 기하급수적으로 늘어날 것이다. 적당히 크기를 줄이고 특정 특징을 강조하기 위해 pooling layer 사용이 가능하다. stride를 크게 두고 사용하지 않고 pooling layer 사용하는 이유는 stride가 커지면 feature를 잘 뽑아내지 못하면서 (듬성듬성 뽑아내기 때문) 특징에 대한 데이터를 유실할 가능성이 있기 때문이다.
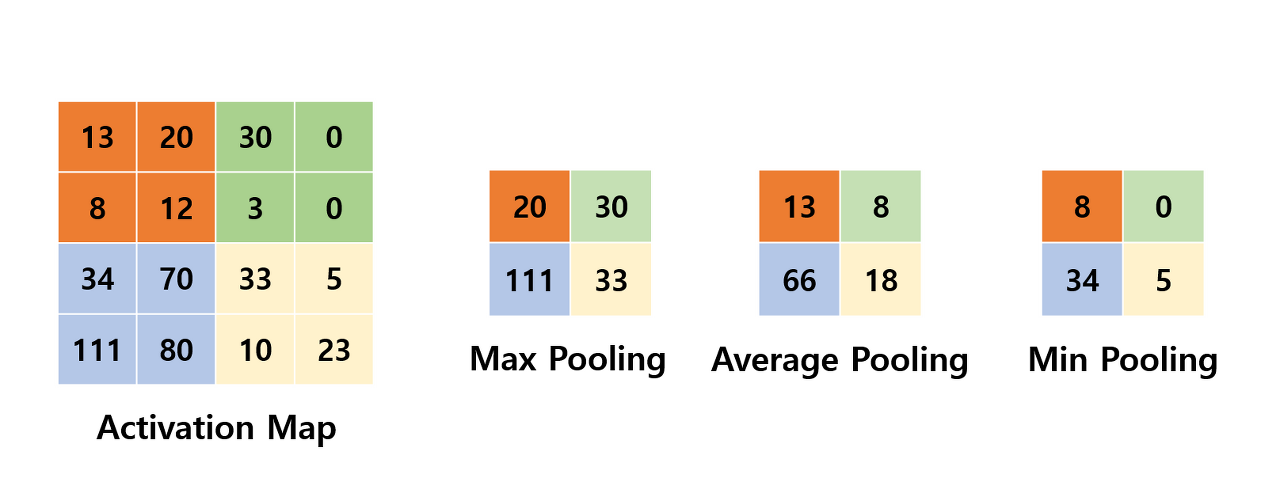
Pooling layer 종류
- Max pooling
- Average pooling
- Min pooling
pooling layer는 최댓값을 구하거나 평균을 구하는 방식으로 동작한다. 일반적으로 pooling의 크기와 stride의 크기를 같게 설정하여 모든 원소가 한 번씩은 처리가 되도록 설정한다.
cnn에서는 대체로 max pool 사용한다. convolution 연산에서는 이미지 데이터에 filter를 mapping 하여 곱과 합 연산을 하여 feature map을 출력하였다면, max pool 연산에서는 activation map에 설정된 크기의 kernel을 mapping 하여 그 중 가장 큰 값 하나를 뽑아내 feature map처럼 모아서 출력하는 것이다. 마찬가지로 padding 사용이 가능하다. 사용하지 않는 경우, size를 원본 보다 작게 줄여서 학습에 용이하게 하고, 사용하는 경우, 특징을 더욱 도드라지게 뽑아낼 수 있다.
Pooling layer 특징
- 학습대상 파라미터가 없음
- kernel size, stride 존재
- Pooling layer를 통과하면 행렬의 크기가 감소함
- Padding 사용 가능
- Pooling layer를 통과해도 channel 수는 변경없음
CNN 전체 구조

특징 추출 단계 (Feature Extraction)
- Convolution Layer : 필터를 통해 이미지의 특징을 추출
- Pooling Layer : 특징을 강화시키고 이미지의 크기를 줄임 (Convolution과 Pooling을 반복하면서 이미지의 feature를 추출)
이미지 분류 단계 (Classification)
- Flatten Layer : 데이터 타입을 FC네트워크 형태로 변경. 입력데이터의 shape 변경만 수행
- Softmax Layer : Classification수행
이처럼 CNN은 Convolution과 Pooling을 반복적으로 사용하면서 불변하는 특징을 찾고, 그 특징을 입력데이터로 Fully-connected 신경망에 보내 Classification을 수행합니다.
기타 CNN에 대한 개념 설명 참조 사이트
'Big data & AI' 카테고리의 다른 글
| Deep learning 예제: CNN 활용 과정 1 (0) | 2020.01.14 |
|---|---|
| Deep learning: 과적합 해결 dropout (0) | 2020.01.13 |
| Deep learning: Xavier 초기값 및 초기화 (0) | 2020.01.13 |
| Deep learning: ReLU 함수 (0) | 2020.01.13 |
| Deep learning 예제: MNIST (0) | 2020.01.13 |
